如何减少检索延迟
先决条件
本指南假定你熟悉以下概念
减少检索延迟的一种方法是使用名为“自适应检索”的技术。 MatryoshkaRetriever 使用 Matryoshka 表示学习 (MRL) 技术分两步检索给定查询的文档
第一步:使用 MRL 嵌入的低维子向量进行初始、快速但不太准确的搜索。
第二步:使用完整的高维嵌入对第一步中排名前的结果进行重新排序,以提高准确性。
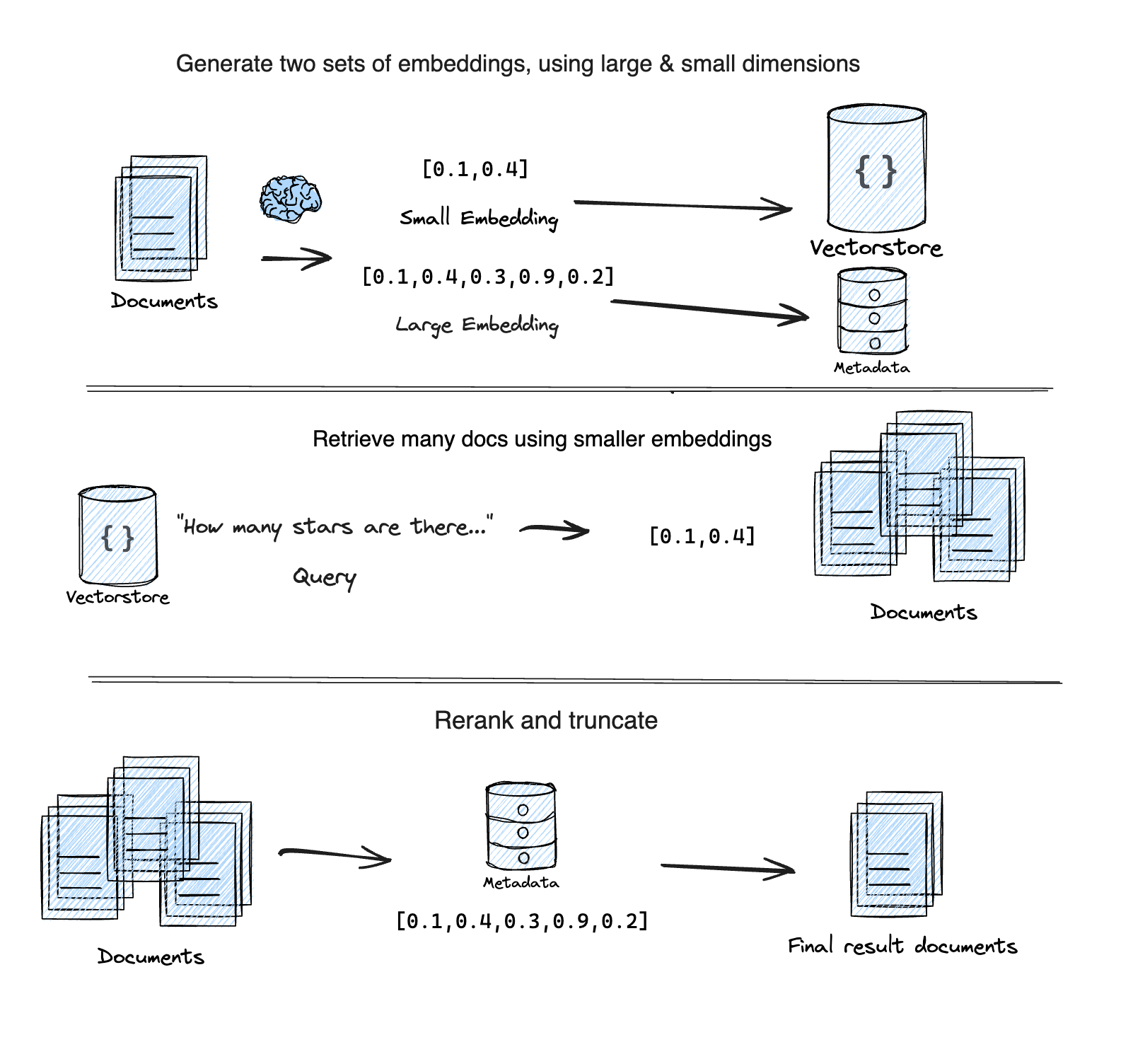
它基于这篇文章 Supabase 博客文章 "Matryoshka 嵌入:使用自适应检索加快 OpenAI 向量搜索".
设置
提示
- npm
- Yarn
- pnpm
npm install @langchain/openai @langchain/community
yarn add @langchain/openai @langchain/community
pnpm add @langchain/openai @langchain/community
要遵循下面的示例,你需要一个 OpenAI API 密钥
export OPENAI_API_KEY=your-api-key
我们还将使用chroma 作为我们的向量存储。按照 此处 的说明进行设置。
import { MatryoshkaRetriever } from "langchain/retrievers/matryoshka_retriever";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { faker } from "@faker-js/faker";
const smallEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
dimensions: 512, // Min number for small
});
const largeEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large",
dimensions: 3072, // Max number for large
});
const vectorStore = new Chroma(smallEmbeddings, {
numDimensions: 512,
});
const retriever = new MatryoshkaRetriever({
vectorStore,
largeEmbeddingModel: largeEmbeddings,
largeK: 5,
});
const irrelevantDocs = Array.from({ length: 250 }).map(
() =>
new Document({
pageContent: faker.lorem.word(7), // Similar length to the relevant docs
})
);
const relevantDocs = [
new Document({
pageContent: "LangChain is an open source github repo",
}),
new Document({
pageContent: "There are JS and PY versions of the LangChain github repos",
}),
new Document({
pageContent: "LangGraph is a new open source library by the LangChain team",
}),
new Document({
pageContent: "LangChain announced GA of LangSmith last week!",
}),
new Document({
pageContent: "I heart LangChain",
}),
];
const allDocs = [...irrelevantDocs, ...relevantDocs];
/**
* IMPORTANT:
* The `addDocuments` method on `MatryoshkaRetriever` will
* generate the small AND large embeddings for all documents.
*/
await retriever.addDocuments(allDocs);
const query = "What is LangChain?";
const results = await retriever.invoke(query);
console.log(results.map(({ pageContent }) => pageContent).join("\n"));
/**
I heart LangChain
LangGraph is a new open source library by the LangChain team
LangChain is an open source github repo
LangChain announced GA of LangSmith last week!
There are JS and PY versions of the LangChain github repos
*/
API 参考
- MatryoshkaRetriever 来自
langchain/retrievers/matryoshka_retriever - Chroma 来自
@langchain/community/vectorstores/chroma - OpenAIEmbeddings 来自
@langchain/openai - Document 来自
@langchain/core/documents
注意
由于某些向量存储的限制,大型嵌入元数据字段在存储之前被字符串化 (JSON.stringify)。这意味着元数据字段需要在从向量存储中检索时进行解析 (JSON.parse)。
后续步骤
你现在已经学习了一种可以帮助加快检索查询速度的技术。
接下来,查看关于 RAG 的更广泛教程,或查看本节了解如何在任何数据源上创建自己的自定义检索器。