嵌入模型
此概念概述侧重于基于文本的嵌入模型。
嵌入模型也可以是多模态的,但 LangChain 目前不支持此类模型。
想象一下,能够在一个简洁的表示中捕捉任何文本的本质——一条推文、文档或书籍。这就是嵌入模型的强大之处,它是许多检索系统的核心。嵌入模型将人类语言转换为机器可以理解和快速准确地比较的格式。这些模型将文本作为输入,并生成一个固定长度的数字数组,即文本语义含义的数值指纹。嵌入使搜索系统不仅可以基于关键词匹配,还可以基于语义理解来查找相关文档。
关键概念
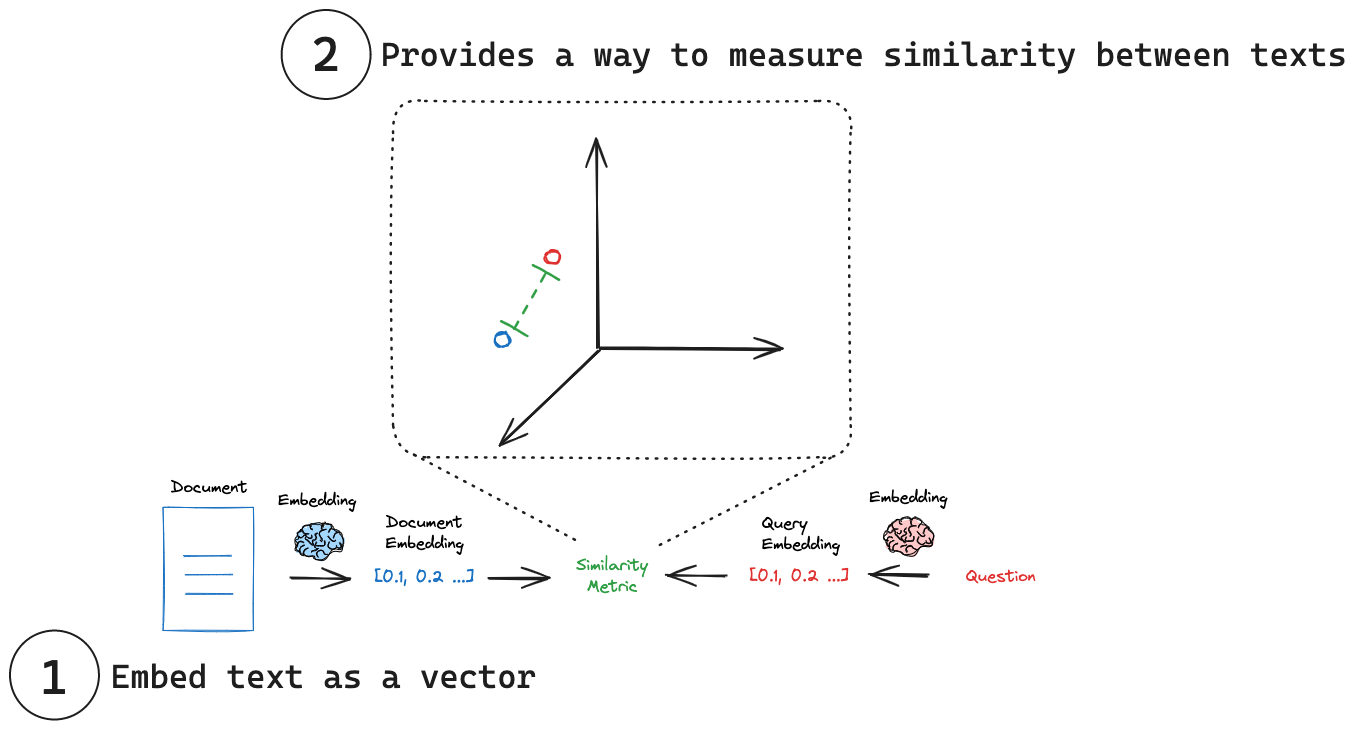
(1) 将文本嵌入为向量:嵌入将文本转换为数值向量表示。
(2) 测量相似度:可以使用简单的数学运算比较嵌入向量。
嵌入
历史背景
多年来,嵌入模型的格局发生了显著变化。2018 年,谷歌推出了 BERT(Bidirectional Encoder Representations from Transformers,来自 Transformer 的双向编码器表示),这是一个关键时刻。BERT 应用 Transformer 模型将文本嵌入为简单的向量表示,从而在各种 NLP 任务中实现了前所未有的性能。然而,BERT 没有针对高效生成句子嵌入进行优化。这种限制促使了 SBERT(Sentence-BERT,句子 BERT) 的创建,它调整了 BERT 架构以生成语义丰富的句子嵌入,可以通过余弦相似度等相似度指标轻松比较,从而大大降低了查找相似句子等任务的计算开销。如今,嵌入模型生态系统是多样化的,许多提供商都提供自己的实现。为了驾驭这种多样性,研究人员和从业者通常会求助于大规模文本嵌入基准 (MTEB) 这里 等基准进行客观比较。
- 请参阅开创性的 BERT 论文。
- 请参阅 Cameron Wolfe 关于嵌入模型的 精彩评论。
- 请参阅大规模文本嵌入基准 (MTEB) 排行榜,以获得嵌入模型的全面概述。
接口
LangChain 提供了一个通用的接口来使用它们,为常见操作提供标准方法。这个通用接口通过两种中心方法简化了与各种嵌入提供商的交互
embedDocuments:用于嵌入多个文本(文档)embedQuery:用于嵌入单个文本(查询)
这种区分很重要,因为一些提供商对文档(要搜索的文档)和查询(搜索输入本身)采用不同的嵌入策略。为了说明,以下是一个使用 LangChain 的 .embedDocuments 方法嵌入字符串列表的实际示例
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddingsModel = new OpenAIEmbeddings();
const embeddings = await embeddingsModel.embedDocuments([
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!",
]);
console.log(`(${embeddings.length}, ${embeddings[0].length})`);
// (5, 1536)
为了方便起见,您还可以使用 embedQuery 方法嵌入单个文本
const queryEmbedding = await embeddingsModel.embedQuery(
"What is the meaning of life?"
);
- 请参阅 LangChain 嵌入模型集成的完整列表。
- 请参阅这些 操作指南,了解如何使用嵌入模型。
集成
LangChain 提供了许多嵌入模型集成,您可以在嵌入模型集成页面上找到它们。
测量相似度
每个嵌入本质上都是一组坐标,通常在高维空间中。在这个空间中,每个点(嵌入)的位置反映了其对应文本的含义。正如相似的词语在词库中可能彼此接近一样,相似的概念最终在这个嵌入空间中也彼此接近。这允许不同文本片段之间进行直观的比较。通过将文本简化为这些数值表示,我们可以使用简单的数学运算来快速测量两个文本片段的相似程度,而与其原始长度或结构无关。一些常见的相似度指标包括
- 余弦相似度:测量两个向量之间夹角的余弦值。
- 欧几里得距离:测量两点之间的直线距离。
- 点积:测量一个向量在另一个向量上的投影。
相似度指标的选择应根据模型来选择。例如,OpenAI 建议为其嵌入使用余弦相似度,这可以很容易地实现
function cosineSimilarity(vec1: number[], vec2: number[]): number {
const dotProduct = vec1.reduce((sum, val, i) => sum + val * vec2[i], 0);
const norm1 = Math.sqrt(vec1.reduce((sum, val) => sum + val * val, 0));
const norm2 = Math.sqrt(vec2.reduce((sum, val) => sum + val * val, 0));
return dotProduct / (norm1 * norm2);
}
const similarity = cosineSimilarity(queryResult, documentResult);
console.log("Cosine Similarity:", similarity);