检索
此处回顾的一些概念利用模型来生成查询(例如,用于 SQL 或图数据库)。这样做存在内在风险。请确保您的数据库连接权限的范围尽可能窄,以满足您的应用程序的需求。这将减轻(但不能消除)构建能够查询数据库的模型驱动系统的风险。有关一般安全最佳实践的更多信息,请参阅我们的安全指南。
概述
检索系统是许多 AI 应用的基础,可以有效地从大型数据集中识别相关信息。这些系统可以适应各种数据格式
- 非结构化文本(例如,文档)通常存储在向量存储或词汇搜索索引中。
- 结构化数据通常存储在具有定义模式的关系数据库或图数据库中。
尽管数据格式多种多样,但现代 AI 应用越来越多地致力于通过自然语言界面访问所有类型的数据。模型在此过程中发挥着至关重要的作用,它们将自然语言查询转换为与底层搜索索引或数据库兼容的格式。这种转换使得与复杂数据结构的交互更加直观和灵活。
关键概念
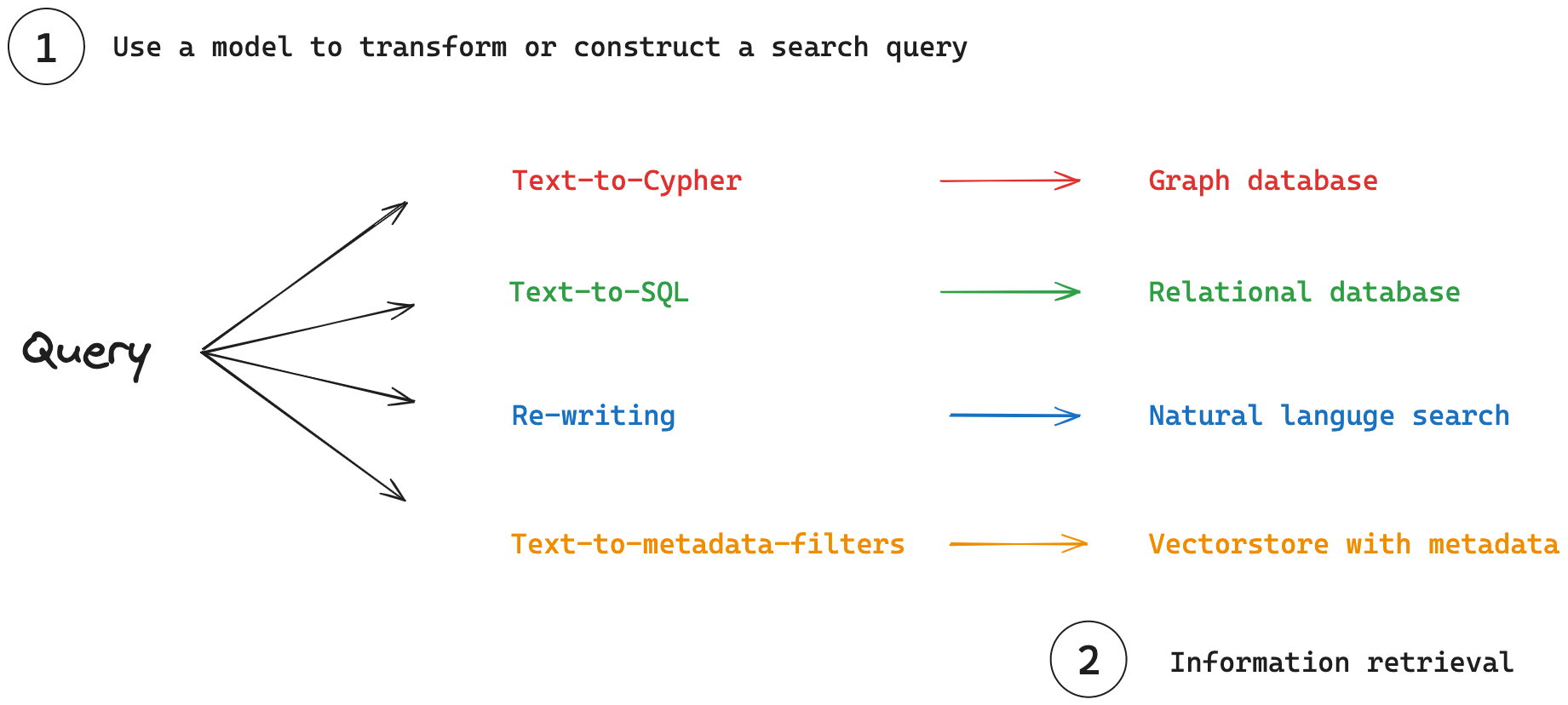
(1)查询分析:模型转换或构建搜索查询以优化检索的过程。
(2)信息检索:搜索查询用于从各种检索系统中获取信息。
查询分析
虽然用户通常更喜欢使用自然语言与检索系统交互,但检索系统可能需要特定的查询语法,或者从特定的关键字中获益。查询分析充当原始用户输入和优化搜索查询之间的桥梁。查询分析的一些常见应用包括
- 查询重写:可以重写或扩展查询以改进语义或词汇搜索。
- 查询构建:搜索索引可能需要结构化查询(例如,数据库的 SQL)。
查询分析使用模型从原始用户输入转换或构建优化的搜索查询。
查询重写
理想情况下,检索系统应该能够处理各种各样的用户输入,从简单且措辞不当的查询到复杂、多方面的问题。为了实现这种通用性,一种流行的方法是使用模型将原始用户查询转换为更有效的搜索查询。这种转换的范围可以从简单的关键词提取到复杂的查询扩展和重构。以下是在非结构化数据检索中使用模型进行查询分析的一些主要优势
- 查询澄清:模型可以改写模糊或措辞不当的查询,以使其更清晰。
- 语义理解:它们可以捕捉查询背后的意图,超越字面关键词匹配。
- 查询扩展:模型可以生成相关的术语或概念,以扩大搜索范围。
- 复杂查询处理:它们可以将多部分问题分解为更简单的子查询。
已经开发了各种技术来利用模型进行查询重写,包括
| 名称 | 何时使用 | 描述 |
|---|---|---|
| 分解 | 当一个问题可以分解为更小的子问题时。 | 将一个问题分解为一组子问题/问题,这些子问题/问题可以按顺序解决(使用第一个问题的答案 + 检索来回答第二个问题)或并行解决(将每个答案合并为最终答案)。 |
| 后退一步 | 当需要更高层次的概念理解时。 | 首先提示 LLM 询问关于更高层次概念或原理的通用后退一步问题,并检索关于它们的相关事实。使用此基础来帮助回答用户问题。论文。 |
| HyDE | 如果您在使用原始用户输入检索相关文档时遇到挑战。 | 使用 LLM 将问题转换为回答问题的假设文档。使用嵌入的假设文档来检索真实文档,前提是文档-文档相似性搜索可以产生更相关的匹配。论文。 |
例如,查询分解可以使用提示和强制子问题列表的结构化输出来简单地完成。然后,这些子问题可以在下游检索系统上顺序或并行运行。
import { z } from "zod";
import { ChatOpenAI } from "@langchain/openai";
import { SystemMessage, HumanMessage } from "@langchain/core/messages";
// Define a zod object for the structured output
const Questions = z.object({
questions: z
.array(z.string())
.describe("A list of sub-questions related to the input query."),
});
// Create an instance of the model and enforce the output structure
const model = new ChatOpenAI({ modelName: "gpt-4", temperature: 0 });
const structuredModel = model.withStructuredOutput(Questions);
// Define the system prompt
const system = `You are a helpful assistant that generates multiple sub-questions related to an input question.
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation.`;
// Pass the question to the model
const question =
"What are the main components of an LLM-powered autonomous agent system?";
const questions = await structuredModel.invoke([
new SystemMessage(system),
new HumanMessage(question),
]);
查询构建
查询分析还可以侧重于将自然语言查询转换为专门的查询语言或过滤器。这种转换对于有效地与各种类型的数据库(这些数据库存储结构化或半结构化数据)进行交互至关重要。
结构化数据示例:对于关系数据库和图数据库,使用领域特定语言 (DSL) 来查询数据。
- 文本到 SQL:将自然语言转换为 SQL,用于关系数据库。
- 文本到 Cypher:将自然语言转换为 Cypher,用于图数据库。
半结构化数据示例:对于向量存储,查询可以将语义搜索与元数据过滤结合起来。
- 自然语言到元数据过滤器:将用户查询转换为适当的元数据过滤器。
这些方法利用模型来弥合用户意图与不同数据存储系统的特定查询要求之间的差距。以下是一些流行的技术
| 名称 | 何时使用 | 描述 |
|---|---|---|
| 自查询 | 如果用户提出的问题最好通过基于元数据而不是与文本的相似性来获取文档来回答。 | 这使用 LLM 将用户输入转换为两件事:(1)要进行语义查找的字符串,(2)要随附的元数据过滤器。这很有用,因为问题通常是关于文档的元数据(而不是内容本身)。 |
| 文本到 SQL | 如果用户提出的问题需要存储在关系数据库中、可通过 SQL 访问的信息。 | 这使用 LLM 将用户输入转换为 SQL 查询。 |
| 文本到 Cypher | 如果用户提出的问题需要存储在图数据库中、可通过 Cypher 访问的信息。 | 这使用 LLM 将用户输入转换为 Cypher 查询。 |
例如,以下是如何使用 SelfQueryRetriever 将自然语言查询转换为元数据过滤器。
import { SelfQueryRetriever } from "langchain/retrievers/self_query";
import { AttributeInfo } from "langchain/chains/query_constructor";
import { ChatOpenAI } from "@langchain/openai";
const attributeInfo: AttributeInfo[] = schemaForMetadata;
const documentContents = "Brief summary of a movie";
const llm = new ChatOpenAI({ temperature: 0 });
const retriever = SelfQueryRetriever.fromLLM({
llm,
vectorStore,
documentContents,
attributeInfo,
});
- 请参阅我们关于文本到 SQL、文本到 Cypher 和元数据过滤器查询分析的教程。
- 请参阅我们的博客文章概述。
- 请参阅我们关于查询构建的 RAG 从零开始视频。
信息检索
常用检索系统
词汇搜索索引
许多搜索引擎基于将查询中的单词与每个文档中的单词进行匹配。这种方法称为词汇检索,使用搜索算法,这些算法通常基于词频。直觉很简单:一个词在用户的查询和特定文档中都频繁出现,那么该文档可能是一个很好的匹配项。
用于实现此目的的特定数据结构通常是倒排索引。这种类型的索引包含一个单词列表以及每个单词到它在各种文档中出现的位置列表的映射。使用此数据结构,可以有效地将搜索查询中的单词与它们出现的文档进行匹配。BM25 和 TF-IDF 是两种流行的词汇搜索算法。
- 请参阅 BM25 检索器集成。
向量索引
向量索引是索引和存储非结构化数据的另一种方法。请参阅我们关于向量存储的概念指南,以获得详细概述。
简而言之,向量存储不是使用词频,而是使用嵌入模型将文档压缩为高维向量表示。这允许使用简单的数学运算(如余弦相似度)对嵌入向量进行有效的相似性搜索。
关系数据库
关系数据库是许多应用程序中使用的一种基本类型的结构化数据存储。它们将数据组织成具有预定义模式的表,其中每个表代表一个实体或关系。数据存储在行(记录)和列(属性)中,从而可以通过 SQL(结构化查询语言)进行高效的查询和操作。关系数据库擅长维护数据完整性、支持复杂查询以及处理不同数据实体之间的关系。
- 请参阅我们关于使用 SQL 数据库的教程。
图数据库
图数据库是一种专门的数据库,旨在存储和管理高度互连的数据。与传统的关系数据库不同,图数据库使用灵活的结构,该结构由节点(实体)、边(关系)和属性组成。这种结构允许有效地表示和查询复杂的互连数据。图数据库以图形结构存储数据,包括节点、边和属性。它们对于存储和查询数据点之间复杂的关系特别有用,例如社交网络、供应链管理、欺诈检测和推荐服务
- 请参阅我们关于使用图数据库的教程。
- 请参阅 Neo4j 的 LangChain 入门套件。
检索器
LangChain 通过检索器概念为与各种检索系统交互提供了一个统一的接口。该接口非常简单
- 输入:查询(字符串)
- 输出:文档列表(标准化的 LangChain Document 对象)
您可以使用前面提到的任何检索系统创建检索器。我们讨论的查询分析技术在这里特别有用,因为它们为通常需要结构化查询语言的数据库启用了自然语言界面。例如,您可以使用文本到 SQL 转换为 SQL 数据库构建检索器。这允许将自然语言查询(字符串)在幕后转换为 SQL 查询。无论底层检索系统如何,LangChain 中的所有检索器都共享一个通用接口。您可以将它们与简单的 invoke 方法一起使用
const docs = await retriever.invoke(query);