如何进行“自查询”检索
自查询检索器顾名思义,具有自查询的能力。具体来说,给定任何自然语言查询,检索器使用 LLM 编写结构化查询,然后将该结构化查询应用于其底层向量存储。这使得检索器不仅可以使用用户输入的查询与存储文档的内容进行语义相似性比较,还可以从用户查询中提取有关存储文档元数据的过滤器,并执行这些过滤器。
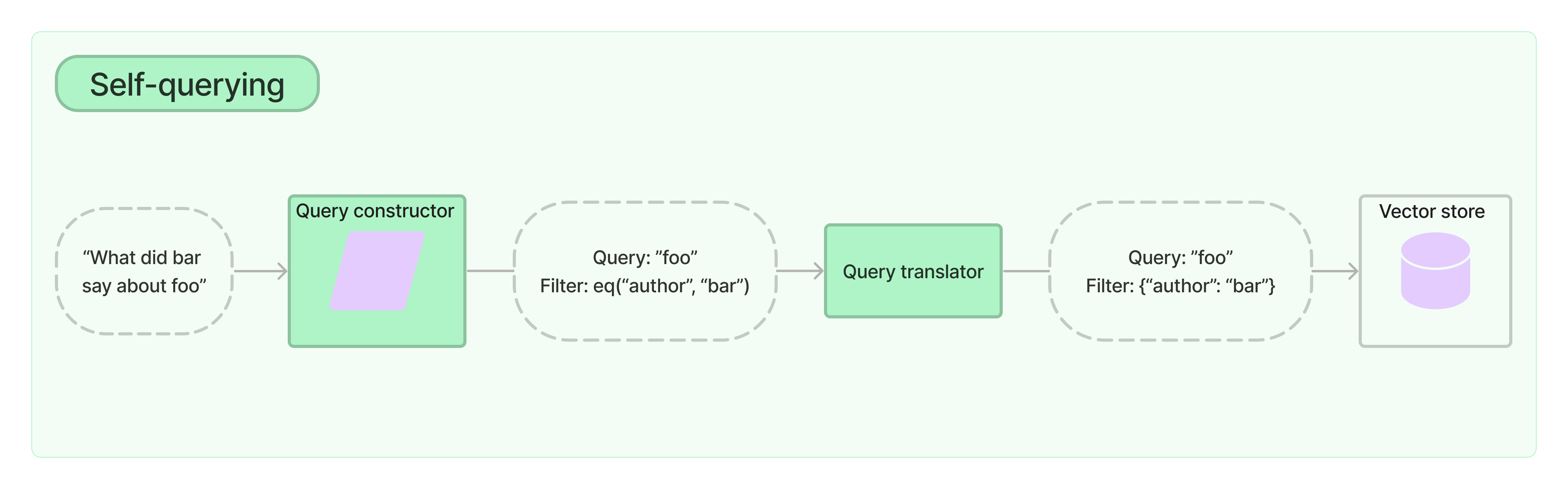
前往集成,查看有关内置支持自查询的向量存储的文档。
开始使用
出于演示目的,我们将使用内存中的、未优化的向量存储。在认真构建时,您应该将其换成受支持的生产就绪型向量存储。
自查询检索器要求您安装 peggy 包作为对等依赖项,并且在此示例中我们还将使用 OpenAI
- npm
- yarn
- pnpm
npm i peggy @langchain/openai @langchain/core
yarn add peggy @langchain/openai @langchain/core
pnpm add peggy @langchain/openai @langchain/core
我们创建了一个小型演示文档集,其中包含电影摘要
import "peggy";
import { Document } from "@langchain/core/documents";
/**
* First, we create a bunch of documents. You can load your own documents here instead.
* Each document has a pageContent and a metadata field. Make sure your metadata matches the AttributeInfo below.
*/
const docs = [
new Document({
pageContent:
"A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata: {
year: 1993,
rating: 7.7,
genre: "science fiction",
length: 122,
},
}),
new Document({
pageContent:
"Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata: {
year: 2010,
director: "Christopher Nolan",
rating: 8.2,
length: 148,
},
}),
new Document({
pageContent:
"A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata: { year: 2006, director: "Satoshi Kon", rating: 8.6 },
}),
new Document({
pageContent:
"A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata: {
year: 2019,
director: "Greta Gerwig",
rating: 8.3,
length: 135,
},
}),
new Document({
pageContent: "Toys come alive and have a blast doing so",
metadata: { year: 1995, genre: "animated", length: 77 },
}),
new Document({
pageContent: "Three men walk into the Zone, three men walk out of the Zone",
metadata: {
year: 1979,
director: "Andrei Tarkovsky",
genre: "science fiction",
rating: 9.9,
},
}),
];
创建我们的自查询检索器
现在我们可以实例化我们的检索器。为此,我们需要预先提供一些关于我们的文档支持的元数据字段的信息,以及文档内容的简短描述。
import { OpenAIEmbeddings, OpenAI } from "@langchain/openai";
import { FunctionalTranslator } from "@langchain/core/structured_query";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { SelfQueryRetriever } from "langchain/retrievers/self_query";
import type { AttributeInfo } from "langchain/chains/query_constructor";
/**
* We define the attributes we want to be able to query on.
* in this case, we want to be able to query on the genre, year, director, rating, and length of the movie.
* We also provide a description of each attribute and the type of the attribute.
* This is used to generate the query prompts.
*/
const attributeInfo: AttributeInfo[] = [
{
name: "genre",
description: "The genre of the movie",
type: "string or array of strings",
},
{
name: "year",
description: "The year the movie was released",
type: "number",
},
{
name: "director",
description: "The director of the movie",
type: "string",
},
{
name: "rating",
description: "The rating of the movie (1-10)",
type: "number",
},
{
name: "length",
description: "The length of the movie in minutes",
type: "number",
},
];
/**
* Next, we instantiate a vector store. This is where we store the embeddings of the documents.
* We also need to provide an embeddings object. This is used to embed the documents.
*/
const embeddings = new OpenAIEmbeddings();
const llm = new OpenAI();
const documentContents = "Brief summary of a movie";
const vectorStore = await MemoryVectorStore.fromDocuments(docs, embeddings);
const selfQueryRetriever = SelfQueryRetriever.fromLLM({
llm,
vectorStore,
documentContents,
attributeInfo,
/**
* We need to use a translator that translates the queries into a
* filter format that the vector store can understand. We provide a basic translator
* translator here, but you can create your own translator by extending BaseTranslator
* abstract class. Note that the vector store needs to support filtering on the metadata
* attributes you want to query on.
*/
structuredQueryTranslator: new FunctionalTranslator(),
});
测试一下
现在我们可以实际尝试使用我们的检索器了!
我们可以提出诸如“哪些电影少于 90 分钟?”或“哪些电影的评分高于 8.5?”之类的问题。我们还可以提出诸如“哪些电影是喜剧片或戏剧片,并且少于 90 分钟?”之类的问题。检索器中的转换器将自动将这些问题转换为可用于检索文档的向量存储过滤器。
await selfQueryRetriever.invoke("Which movies are less than 90 minutes?");
[
Document {
pageContent: "Toys come alive and have a blast doing so",
metadata: { year: 1995, genre: "animated", length: 77 }
}
]
await selfQueryRetriever.invoke("Which movies are rated higher than 8.5?");
[
Document {
pageContent: "A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception"... 16 more characters,
metadata: { year: 2006, director: "Satoshi Kon", rating: 8.6 }
},
Document {
pageContent: "Three men walk into the Zone, three men walk out of the Zone",
metadata: {
year: 1979,
director: "Andrei Tarkovsky",
genre: "science fiction",
rating: 9.9
}
}
]
await selfQueryRetriever.invoke("Which movies are directed by Greta Gerwig?");
[
Document {
pageContent: "A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata: { year: 2019, director: "Greta Gerwig", rating: 8.3, length: 135 }
}
]
await selfQueryRetriever.invoke(
"Which movies are either comedy or drama and are less than 90 minutes?"
);
[
Document {
pageContent: "Toys come alive and have a blast doing so",
metadata: { year: 1995, genre: "animated", length: 77 }
}
]
下一步
您现在已经了解了如何使用 SelfQueryRetriever 根据原始问题生成向量存储过滤器。
接下来,您可以查看当前支持自查询的向量存储列表。